Menu
Publication: Distributed Decomposed Data Analytics in Fog Enabled IoT Deployments
Tags:
‘Internet of Things (IoT)’. It is estimated that there will be 1 trillion interconnected IoT devices by 2025, which are expected to generate an unprecedented number of unbounded data streams that demands a paradigm shift when it comes to data analytics.
The increasing range of real-world IoT deployments essentially increase the sources of data generation, thereby globally strengthening the challenges already being faced in the Big Data space, particularly regarding moving data from one end (i.e. from data sources such as sensor/IoT devices at the edge level of infrastructure) to the other extreme end (i.e. centralized data centres at the cloud) in the network infrastructure. Sending the entire data set across the extreme ends in the infrastructure becomes an unrealistic solution, specifically in scenarios with constrained network bandwidth and low/no internet connectivity. Instead, approaches that collect data and perform computational processing near the source of data itself present a more practical alternative to such scenarios, and is beneficial for a number of reasons such as in cases of video, whose transport across infrastructure can claim considerable network resources such as the requirement for storage at each node from source to destinationWhile IoT deployments vary across use cases, the most prominently common underlying aim is to analyse the data generated from the devices to achieve a specific set objective.
IoT, Fog Computing and Decomposition of Data Analytics Programs:
In the existing approaches for data analytics in IoT, all data from an IoT deployment is collected at a centralized location such as server(s) in data centre (i.e. cloud) and is then subjected to the desired data analytics model. Data in these IoT deployments moves from ‘things’ to cloud, and along this continuum passes through a number of network devices such as routers, gateways, etc. Each of these devices can be a potential candidate to host partial computing analytics capability to analyse the data, and further sending the calculated partial results instead of sending the raw data to cloud. The edge of the network in such deployments can act as a potential site to host what we call ‘decomposed analytic computing units’ (Figure 1) to reduce the amount of data being transferred to cloud, and provide the same quality of analytics results.
Fog computing has recently emerged as a potential architecture for scaling IoT network applications. It aims to provide computing resources and services closer to the end devices at the edge of the network along things to cloud continuum. The capabilities of the computing gateways comes as an important aspect of fog computing architecture for IoT based applications. Depending on the IoT deployment, a fog node can range from a dedicated industrial router/gateway to a smartphone, a wearable smartwatch, and so on.
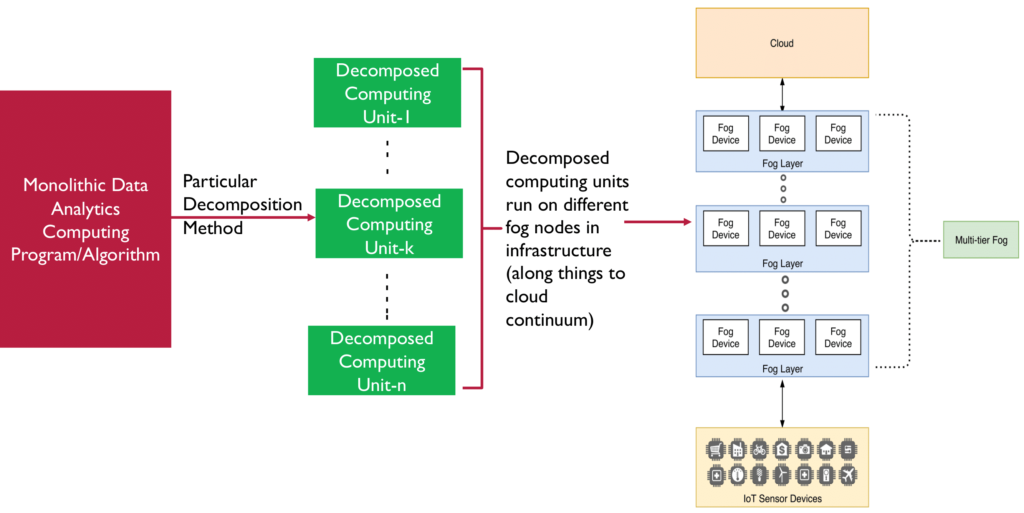 Figure 1– Decomposition of data analytics computing program into decomposed computing units and placing those computing units onto different fog nodes in the infrastructure. Note that the infrastructure architecture considered is most common and widely used three tier IoT-Fog-Cloud architecture (with nested multi-tier fog).
Figure 1– Decomposition of data analytics computing program into decomposed computing units and placing those computing units onto different fog nodes in the infrastructure. Note that the infrastructure architecture considered is most common and widely used three tier IoT-Fog-Cloud architecture (with nested multi-tier fog).
Need to decompose data analytics programs:
Why not to use the whole analytics program on the fog device, and why the decomposed computing units?
The justification for the above involves resource constraints. Contrary to the cloud which can be thought of as ‘resource rich’, the fog devices are resource constrained in nature whereby resource scaling (up/down and horizontal/vertical) cannot be done dynamically. The fog devices are already performing their fundamental computing/network operation (for e.g. in case of router as a fog device, it is already forwarding the packets to the set destination), so these operations are already utilizing the available resources (CPU, RAM and bandwidth) on it. An additional deployment of a complete data analytics computing program/algorithm on the said resource might lead to full utilization of resources on device as the workload or data input increases and also affect its fundamental network operation. Hence, the approach of decomposed computing units seems ideal in an IoT environment with fog assistance.
We presented the fog-specific decomposition of multivariate linear regression as the predictive analytic model in our work using the statistical query model and summation form. To illustrate the benefits of the proposed approach, the experiment conducted used openly available air-quality dataset from UCI repository that contains sensed values of parameters which are used to measure air quality in a region.
The results show an 80% reduction in the amount of data (Figure 2) transferred to the cloud using the proposed fog-based distributed data analytics approach as compared to the conventional cloud-based approach.
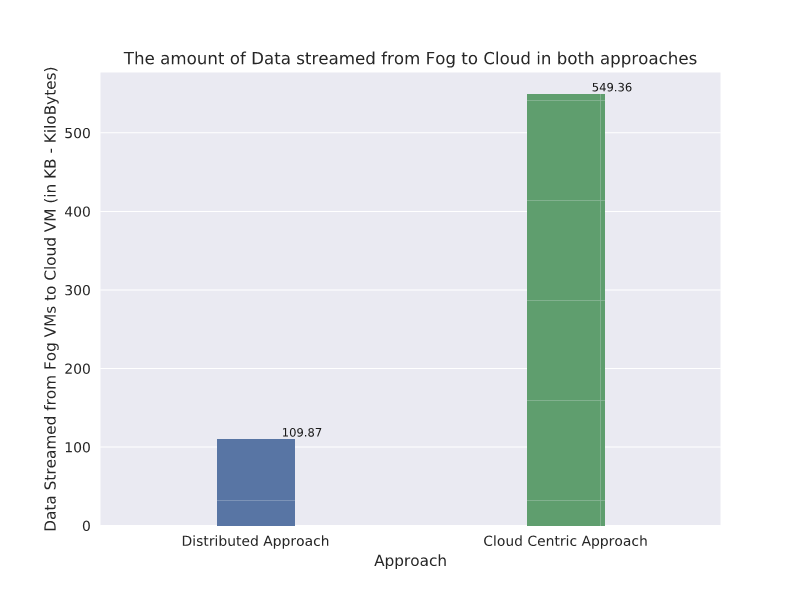 Figure 2– Reduction in amount of data being streamed from fog VMs to cloud VM in fog based distributed approach.
Figure 2– Reduction in amount of data being streamed from fog VMs to cloud VM in fog based distributed approach.
Further, the scatter plot presented in Figure 3 shows that our proposed approach attains same quality of analytics as the cloud centric approach, and they both trace out each other.
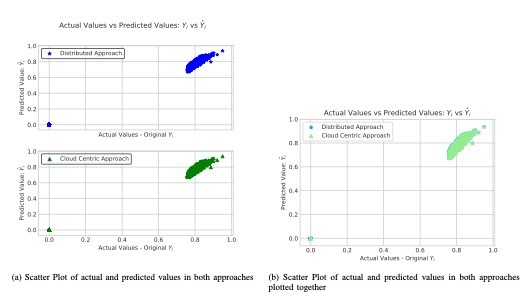 Figure 3– Scatter plot that shows that fog based distributed analytics and cloud centric analytics approach both trace out each other, and that quality of analytics remains preserved in fog based distributed approach.
Figure 3– Scatter plot that shows that fog based distributed analytics and cloud centric analytics approach both trace out each other, and that quality of analytics remains preserved in fog based distributed approach.
Publication: Distributed Decomposed Data Analytics in Fog Enabled IoT Deployments
Authors: Mohit Taneja,Nikita Jalodia, Alan Davy
Journal: IEEE Access, vol. 7, pp. 40969-40981, 2019. doi: 10.1109/ACCESS.2019.2907808
]]>

